微软会谈关于HoloLens交互模型
微软昨天在博客中HoloLens交互模型。基本上有,你可以用HoloLens互动三个方面。使用你的目光,手势和语音。凝视是最自然的。在任何时候,HoloLens会知道你的脑袋是和你正在寻找什么。此信息有助于系统准确地决定什么兼备的姿态和声音应该把目标定。
三个关键要素投入上HoloLens:
视线:用眼睛注视物体,定位目标。
视线是一种最自然的交互方式。在HoloLens中,设备能够时刻感知你的头部所处的位置以及你面前的物体。通过视线,系统能够感知到你所关注的物体,从而建立起“上下文信息”,这是手势和语音操作的前提。
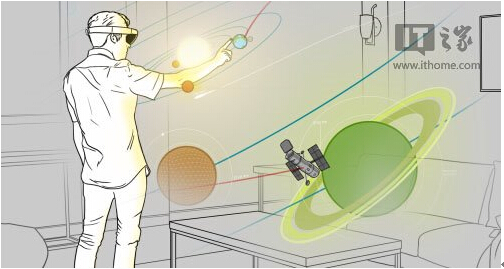
以参与投票的创意之一“水族馆”为例,你可能需要查看某个动物的更多细节,HoloLens正是通过你的眼睛视线来确定目标的。确定目标之后,如果需要查看细节,就需要手势来完成了。

手势:一种“空中点击”的交互方式,主要用于选择。
手势是HoloLens的基本操作方式,只需要抬起手臂,用食指点击即可。通过眼睛视线和手指就能够完成目前我们在显示屏幕所能做的一切事情了。不过,在HoloLens中还可以实现更多,那就是语音控制。
语音:可完全访问Win10语音引擎。
因为HoloLens同样是一台Win10设备,因此可使用windows10中的完整语音引擎。HoloLens内置的麦克风阵列可为语音识别提供高质量语音信号。由于设备已通过视线确定了用户关注的目标,建立了上下文信息,因此HoloLens中的语音命令更加灵活,不需要再额外提供更多前提信息。
以星系探索创意为例,在交互过程中,用户可以随时通过语音命令进行空间导航。






 苏公网安备32032202000432
苏公网安备32032202000432